I’m using OS X at my MBP as a main operation system and iStat Pro widget
for Dashboard to monitor temps, processes, etc.
After upgrading to OS X 10.8 Mountain Lion the processes section was not working.
Here is a small instruction to make processes be displayed again.
Open iStat Pro widget directory, it is located in ~/Library/Widgets/iStat\ Pro.wdgt/
or /Library/Widgets/iStat\ Pro.wdgt/ (in Finder you should use Show Package Contents in context menu
of the specified folder to open the widget’s contents);
If you are using horizontal (wide) widget edit the Wide.js file and if
vertical (tall) - Tall.js;
Find function WideSkinController.prototype.updateProcesses = function(){ and
replace all PID|$1 with PID| $1 (add space after pipe) in this section. So, you should
get something like this:
I create SSH tunnels every day and this article is a small introduction into the SSH tunneling
(also known as “port forwarding”).
A secure shell (SSH) tunnel consists of an encrypted tunnel created through a SSH protocol connection.
Users may set up SSH tunnels to transfer unencrypted traffic over a network through an encrypted channel.
SSH is typically used to log into a remote machine and execute commands, but it also supports tunneling,
forwarding TCP ports and X11 connections; it can transfer files using the associated SSH file transfer (SFTP)
or secure copy (SCP) protocols. Also tunnels provide an ability to bypass firewalls :)
So, let’s start. Ports can be forwarded in three ways:
Local port forwarding;
Remote port forwarding;
Dynamic port forwarding (proxy).
Wikipedia says that:
Port forwarding or port mapping is a name given to the combined technique of
* translating the address and/or port number of a packet to a new destination
* possibly accepting such packet(s) in a packet filter (firewall)
* forwarding the packet according to the routing table.
Tunneling with local port forwarding
Let’s imagine that there are some computers with specific abilities:
work - can’t access target (for example, target is blocked by firewall or target can be
unaccessible from the work’s network)
bridge (gateway) - accessible from work and can access target (need to have IP accessible from work)
So, we want to access target throw the global machine.
Access from work computer to some external banned resource
To create the SSH tunnel you should execute the following command from work (local) machine:
Now the SSH client at work will connect to the SSHd running at bridge and bind <target-host>:<target-port>
to listen for local requests to [<local-address-to-listen>:]<local-port-to-listen>. At the bridge
end the connection to <target-host>:<target-port> will be created. So work doesn’t need to know how to connect to
<target-host>:<target-port>, only bridge needs to worry about that. The channel between work and bridge will be
encrypted (SSH tunnel), but the connection between bridge and <target-host>:<target-port> will be unencrypted.
After executing this command, it is possible to access <target-host>:<target-port> by accessing
[<local-address-to-listen>:]<local-port-to-listen> at work computer. The bridge computer will act as a gateway
which would accept requests from work machine and fetch data/tunnelling it back.
Tunneling with remote port forwarding (reversed tunneling)
Let’s reverse the problem.
home - can’t access target (for example, target is protected by firewall or target can be unacessible from the
home’s network)
bridge (gateway or work) - accessible from home and can access target (need to have IP accessible from home)
To create the SSH tunnel you should execute the following command from bridge (gateway/work) machine:
After executing of this command, the SSH client at bridge will connect to SSHd running at home and create the tunnel.
Then the server will bind [<home-address-to-listen>:]<home-port-to-listen> to listen for incoming requests which would
be routed through the created SSH tunnel between home and gateway. Now it’s possible to access the “internal”
resource <target-host>:<target-port> by accessing [<home-address-to-listen>:]<home-port-to-listen> from the home
machine. The gateway will then create a connection to <target-host>:<target-port> and relay back the response to
home via the created SSH tunnel.
With this approach we need to create the splitted SSH tunnel for each new resource. But SSH provides us an ability to
proxy traffic to any resource using SSH tunnel and it named dynamic port forwarding.
Dynamic port forwarding (proxy)
Dynamic port forwarding provides us an ability to configure one local port for tunnelling data to all remote destinations
using the SOCKS protocol. At the client side of the SSH tunnel a SOCKS proxy would be created and any application that can
work throw SOCKS protocol can use it to access some resources that accessible only from the other host.
First of all, I want to say that the most part of materials for this article I found in the internet.
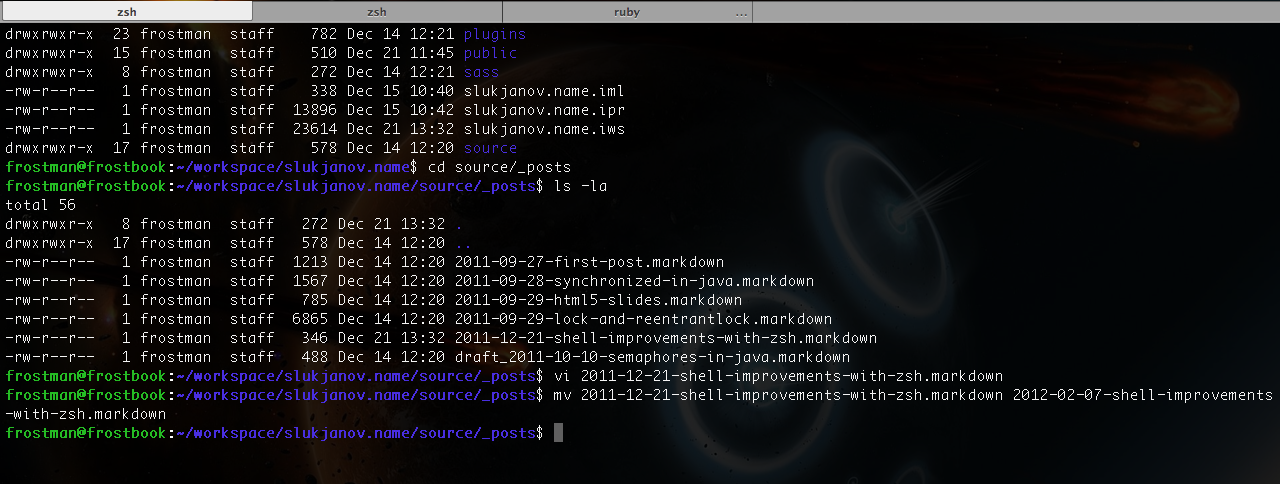
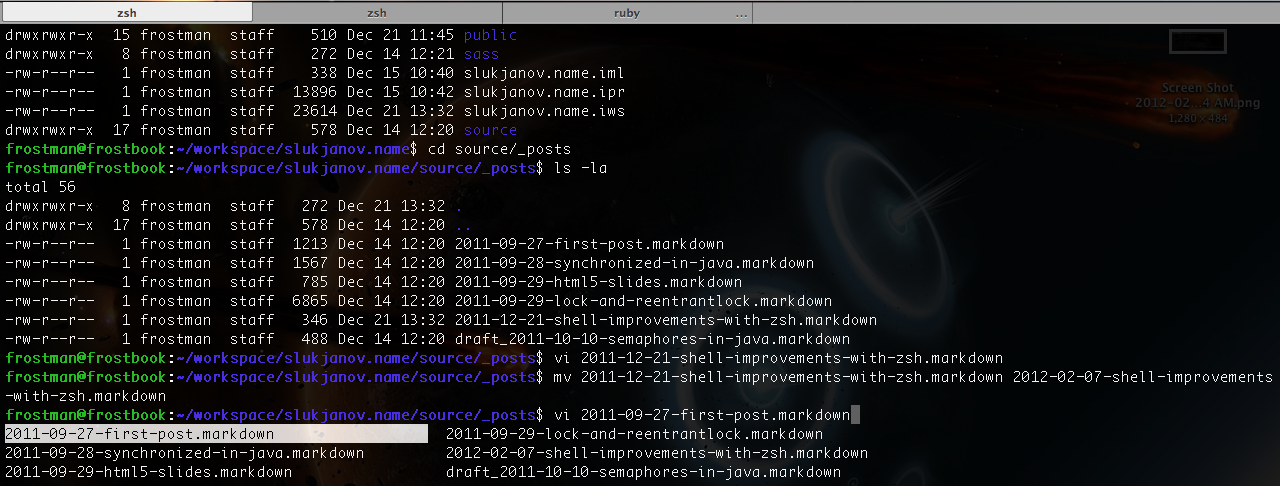
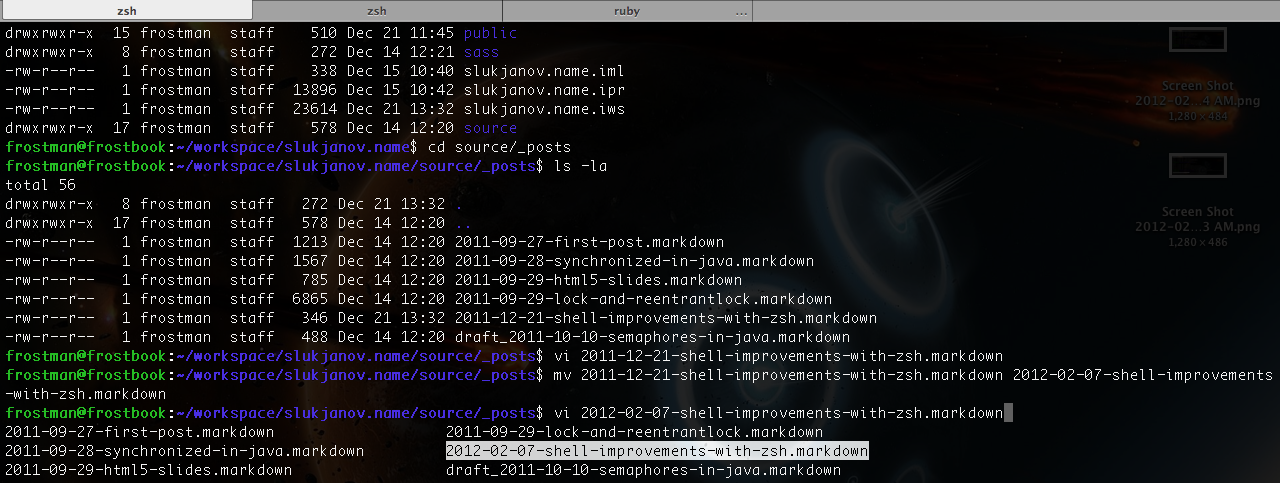
This is an agregation of usefull tips for zsh.
Here is my .zshrc file:
There are a lot of terminal’s improvements, such as extended autocompletion and forced rehash.
I use this configuration at Ubuntu 11.10 and Mac OS X 10.7.3.
You can activate autocompletion by Tab button and control it by arrow keys.
It works with files, directories and hosts.
I don’t have much experience in configuring zsh, but feel free to ask me about something you are intersting in.
Few days ago I encountered a problem with making presentation for techtalk. I didn’t want to use Microsoft PowerPoint
or presentations in Google Docs, because I want to publish slides in my blog. So, it had to be an html5
application and also it had to be ready to be used in browser with projector.
I found some interesting tool to do it. Enjoy it: LandSlide.
The sample presentation with features overview you can find here.
Use ← and → to browse slides.
As we see, it prodives opportunity of acquiring lock by different ways:
if we are using lock() and the lock is not available the current thread will be suspended until the lock will be released;
lockInterruptible() method acquires the lock until the current thread will be interrupted or lock will be released;
tryLock() method acquires the lock only if it is available at the time of invocation (non-blocking, not waiting for
the lock will be released);
if we want to acquire the lock interruptibly with the specified waiting timeout we should use tryLock(...) method.
There is only one method for unlocking the lock: unlock() and it works as it named.
Locks are more flexible and configurable alternative for synchronized methods and statements, but we should remeber that
instead of synchronized, noone will unlock the lock for us if an exception occures or return statement invokes. So,
in most cases, the following idiom should be used:
1234567
Lockl=...;l.lock();try{// some business logic that needs to be synchronized}finally{l.unlock();}
ReadWriteLock is a pair of assotiated locks. First lock is used only for read-only operations (supports multiple
locks at the same time) and the second lock is for write operations (exclusive lock). The read lock can be acquired
only if the write lock is released. When we lock the write lock, it will wait for releasing of all read locks and then acquires.
ReadWriteLock will improve performance in case of using multiple readers and much smaller number of writers, because many of
readers will work at the same time.
Implementations
Java provides two implementations of these locks that we care about - ReentrantLock and ReentrantReadWriteLock.
As you see, both of them are reentrant. It means that a thread can acquire the same lock multiple times without any
issue. In fact reentrant locking increments special thread-personal counter (unlocking - decrements) and the lock will
be released only when counter reaches zero.
Each of lock’s implementations has additional methods that help us. Here are some of them:
for ReentrantLock class:
isHeldByCurrentThread() returns true iff the lock is locked by the current thread;
getHoldCount() returns number (int) of locks on the lock by the current thread;
getQueueLength() returns an estimate number of threads that waits to acquire the lock;
isLocked() returns true if any thread holds this lock and false otherwise;
for ReentrantReadWriteLock class:
isWriteLocked() returns true if someone holds the write lock;
isWriteLockedByCurrentThread() returns true if the lock is locked by the current thread;
getReadHoldCount() returns number (int) of locks on the read lock by the current thread.
Fairness
One of the interesting features of reentrant locks is fairness. When we are creating an instance of ReentrantLock or
ReentrantReadWriteLock we can pass fair flag to the constructor. The difference of fair and non-fair locks is in granting
access policy to threads that wait in the queue to lock the lock. The fair lock grants access to the longest-waiting thread,
so it look like FIFO (First-In-First-Out). A non-fair lock does not guarantee any particular access order.
Performance of fair locks is near to synchronized block and non-fair locks is much faster than them.
By default, all locks are non-fair. Synchronized keyword and statement are non-fair, too. Fair locks have some disadvantages:
performance degradation;
fair locks do not guarantiee fair thread ordering in real world.
Micro-benchmarking in Java is not so good as we want. There are several things that can change results of tests:
JVM warmup (the code becomes faster and faster while its working);
Class loading (all application classes must be loaded);
JIT compilation (JVM needs time to find hot parts of the code);
GC (gc can happen while benchmarking and increase the time much).
Instead of this, I think that we can do some micro-benchmarks to check fair locks performance.
We have T threads, each of them will lock the lock, increment global counter, increment personal counter and unlock the lock.
Test will be ended when the global counter reaches N. So, all threads should have equal values of personal counters
(small deviation can be ignored) with fair lock and different values with non-fair lock. Lets see at average results of running
such micro-benchmark. I ran them for 50 times with N=1000000 and T=10 on my laptop (i3 330m 2.13GHz, 8Gb RAM, JDK 1.7.0)
and aggregated results. ‘Deviation’ - this is how personal counter differs from the expected value (N/T).
Fair Lock
123456
Deviation:
max: 0,3222%
avg: 0,0644%
min: 0,0351%
Average takes: 10304ms
Non-fair Lock
123456
Deviation:
max: 20,1312%
avg: 2,1682%
min: 0,6022%
Average takes: 104ms
You can find sources of the test here.
The results of test match javadoc’s warning about fair locks absolutly:
12345
* Programs using fair locks accessed by many threads
* may display lower overall throughput (i.e., are slower; often much
* slower) than those using the default setting, but have smaller
* variances in times to obtain locks and guarantee lack of
* starvation.
As we see “much slower” is up to 100 times slower!
So, we should remember about all features of locks and their configurations.
I think that we can use ReentrantLock and ReentrantReadWriteLock without any indeterminacy now.
We need synchronizations, when we are writing applications that work with variables from more than one thread. The most simple
way to avoid issues of parallel accessing to variable is to use synchronized statement. In Java there are two ways to use
synchronized:
use statement synchronized with some monitor-object to create critical section (this is also called “synchronized block”):
12345
synchronized(monitorObject) {
// Critical section ::
// this code block can be accessed
// by only one thread at the time
}
mark method with synchronized keyword and then:
if method is static, it is equal to synchronized(DeclaredClass.class) { method body };
if method is not static, it is equal to synchronized(this) { method body }.
So, synchronized takes care about preventing locks in case of multiple read/write access to variables from more than one thread
In the latest JVM (since 1.5) synchronized overhead is very low in case of unused synchronizations (when only one thread
try to enter into the synchronized section at a time), but in the old JVMs synchronized was not optimized.
synchronized keyword is not so flexible and configurable as we want sometimes, so you can read about Lock and ReadWriteLock in Java
here (my next article).
It is the first post in my personal blog. I have planned to write some articles about programming and technologies in it. I think that most of them will be written in english.
This blog is based on Octopress blogging framework and hosted at Github pages.